1 10 443 canary-openshift-ingress-canary.apps.sno.eformat.me
1 10 443 canary-openshift-ingress-canary.apps.baz.eformat.me
Tag: java
Service Discovery and Load Balancing with Stork
25 May 2023
Tags : quarkus, service discovery, stork, load balancing, java
Stork is a service discovery and client-side load-balancing framework. Its one of those critical services you find out you need when doing distributed services programming. Have a read of the docs, it integrates into common open source tooling such as Hashi’s Consul as well as a host of others. Even-though OpenShift/Kubernetes has a built-in support for service discovery and load-balancing, you may need more flexibility to carefully select the service instance you want.
DNS SRV for Service Discovery
I wanted to try out good 'ol fashioned SRV Records as a means to testing out the client side service discovery in Stork. Many people forget that DNS itself supports service discovery for high service availability. It is still very commonly used, especially in mobile/telco.
My test case would be to create a DNS SRV record that queries OpenShift Cluster Canary Application endpoints. I’m using Route53 for DNS so you can read the SRV Records format here. The first three records are priority, weight, and port.
If you curl one of these, you get a Healthcheck requested back if the service is running.
curl https://canary-openshift-ingress-canary.apps.sno.eformat.me
Healthcheck requestedSo, in my example, you can get a full list of SRV record values by querying:
dig SRV canary.demo.redhatlabs.devCoding a Quick Client
For a quick and dirty client to make use of the SRV record I reach out for my favourite tools, yes Perl 🐫🐫🐫 !
Let’s query the SRV record and see if my OpenShift clusters are healthy.
# sudo dnf install -y perl-Net-DNS perl-WWW-Curl
use Net::DNS;
use WWW::Curl::Easy;
use Term::ANSIColor qw(:constants);
sub lookup {
my ($dc) = @_;
my $res = Net::DNS::Resolver-> new;
my $query = $res->send($dc, "SRV");
if ($query) {
foreach $rr ($query->answer) {
next unless $rr->type eq 'SRV';
# return first found
return $rr->target;
}
} else {
print("SRV lookup failed: " . $res->errorstring);
}
return;
}
my $host = lookup("canary.demo.redhatlabs.dev");
print GREEN, $host . "\n", RESET;
my $curl = WWW::Curl::Easy->new;
$curl->setopt(CURLOPT_HEADER,1);
$curl->setopt(CURLOPT_URL, 'https://' . $host);
$curl->setopt(CURLOPT_SSL_VERIFYHOST, 0);
my $retcode = $curl->perform;
if ($retcode == 0) {
print("Transfer went ok\n");
my $response_code = $curl->getinfo(CURLINFO_HTTP_CODE);
print(GREEN, "Received response code: $response_code\n", RESET, "\n");
} else {
print(RED, "An error happened: $retcode ". RESET . $curl->strerror($retcode)." ".$curl->errbuf."\n");
}Of course feel free to run this in a loop :) because each record is equally weighted in the SRV you will get a round-robin behaviour.
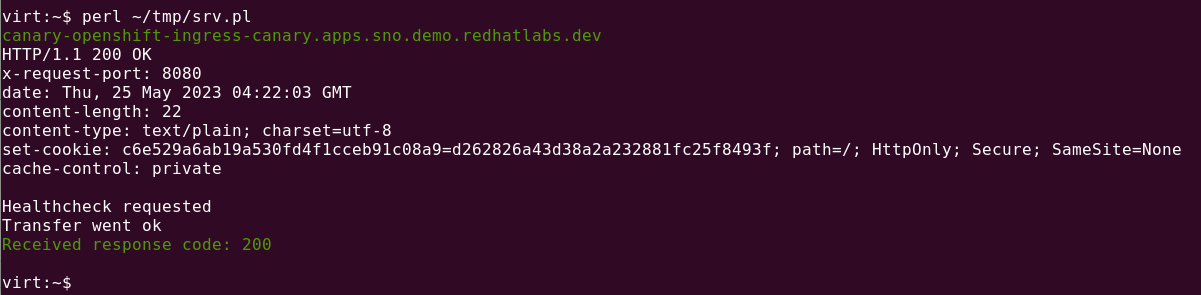
So, looking good so far.
Stork and Java
Of course, the whole point was to try out Stork. Following the Quarkus Stork getting started guide, I used a simple rest client service
and configured the canary stork service as follows:
Unfortunately, this didn’t work as I expected! The SRV record values were resolved to IP addresses instead of returning the DNS name for me to query. The
issue with just an IP address is that Routing in OpenShift requires the HEAD/Location to be set properly so the correct endpoint Route can be routed and queried using HAProxy.
The Stork documentation spells out this DNS resolution process:
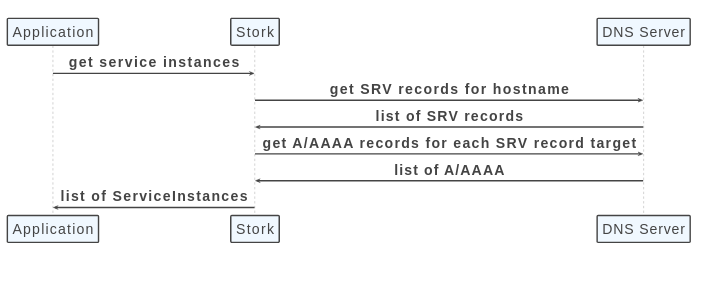
Looking at the source code, led me to submit this PR which adds in an option so that you can skip the DNS resolution step.
So, adding this property using the new version of the Stork library:
quarkus.stork.canary.service-discovery.resolve-srv=falseLeads to the DNS names being returned and no the ip addresses:
Trying out the code and now the Service call works as expected:
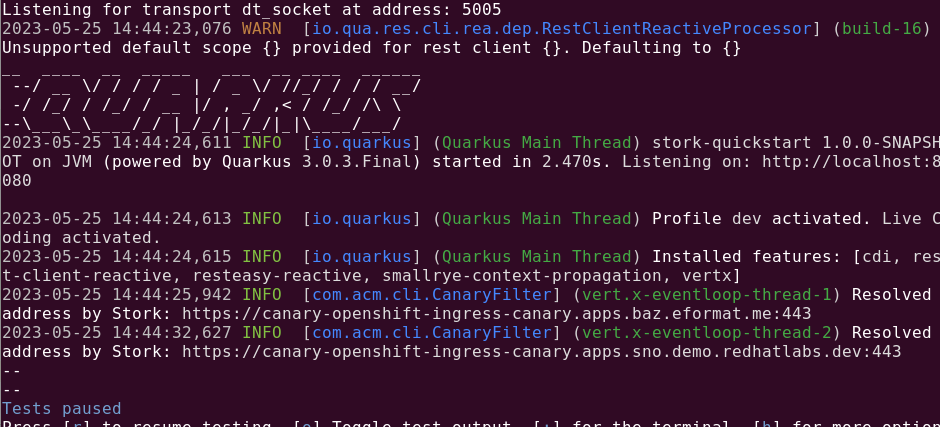
YAY ! 🦍 Checkout the source code here and watch out for the next version of Stork !
AI Constraints Programming with Quarkus and OptaPlanner
04 November 2022
Tags : quarkus, constraints, optaplanner, java
AI on Quarkus: I love it when an OptaPlan comes together
I have been meaning to look at OptaPlanner for ages. All i can say is "Sorry Geoffrey De Smet, you are a goddamn genius and i should have played with OptaPlanner way sooner".
So, i watched this video to see how to get started.
So much fun ! 😁 to code.
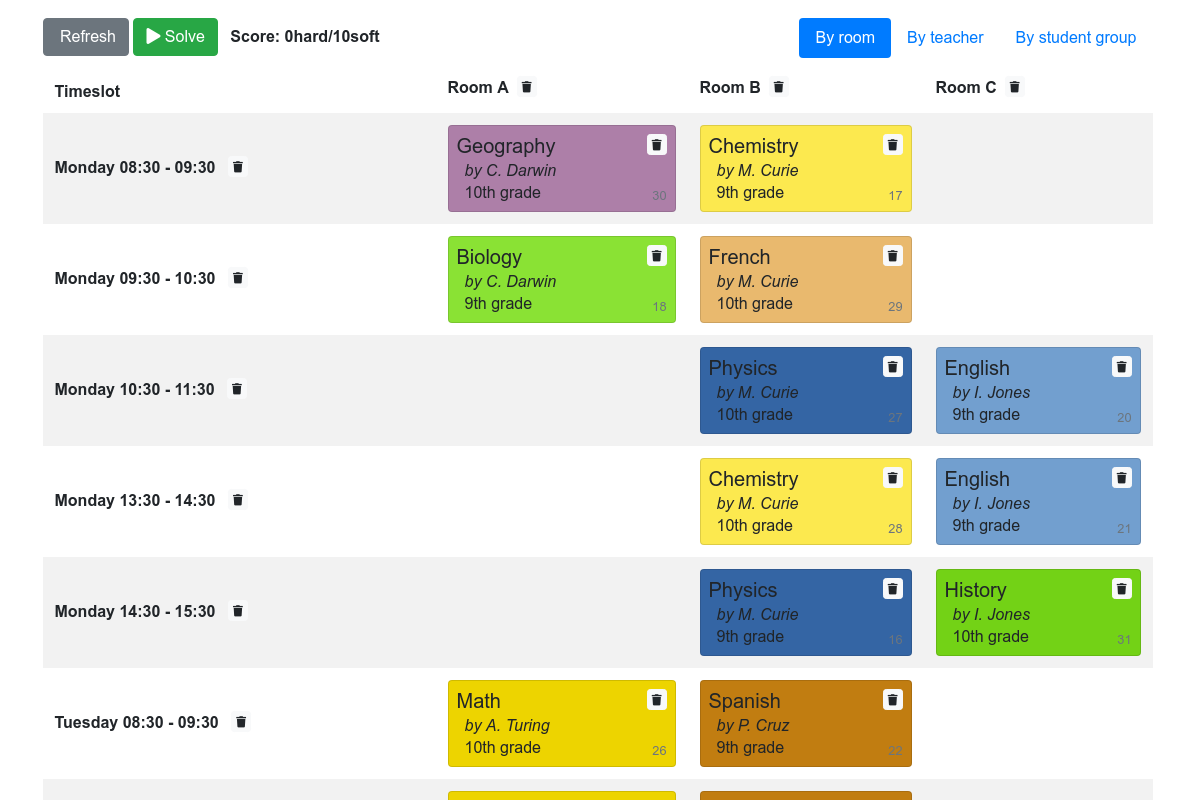
Figure - Quarkus School Timetable
There were a couple of long learnt lessons i remembered whilst playing with the code.
(1) Domain Driven Design
To get at the heart of constraints programming you need a good object class hierarchy, one that is driven by your business domain. Thanks Eric Evans for the gift that keeps giving - DDD (and UML) is perfect to help you out here.

Figure - Class Hierarchy
You need to have a clean and well thought out class heirarchy so that wiring in OptaPlanner will work for you. I can see several iterations and workshop sessions ensuing to get to a workable and correct understanding of the problem domain.
(2) Constraints Programming
I went looking for some code i helped write some 15 years ago ! A Constraint based programming model we had written in C++
We had a whole bunch of Production classes used for calculating different trades types and their values. You added these productions into a solver class heirarcy and if you had the right degrees of freedom your trade calculation would be successful. The beauty of it was the solver would spit out any parameter you had not specified, as long as it was possible to calculate it based on the production rules.
OptaPlanner viscerally reminded me of that code and experience, and started me thinking about how to use it for a similar use case.
I am now a fan 🥰
One last lesson from the OptaPlanner crew was their use of a a new static doc-generation system, their docs are a thing of beauty i have to say, JBake which I am using to write this blog with. Thanks for all the fish 🐟 🐠 Geoff.
OptaPlanner Quickstarts Code - https://github.com/kiegroup/optaplanner-quickstarts
Pulsar Flink
02 November 2022
Tags : streaming, pulsar, flink, java
Pulsar Flink
I have been messing around with yet another streaming demo (YASD). You really just cannot have too many. 🤩
I am a fan of server sent events, why ? because they are HTML5 native. No messing around with web sockets. I have a a small quarkus app that generates stock quotes:
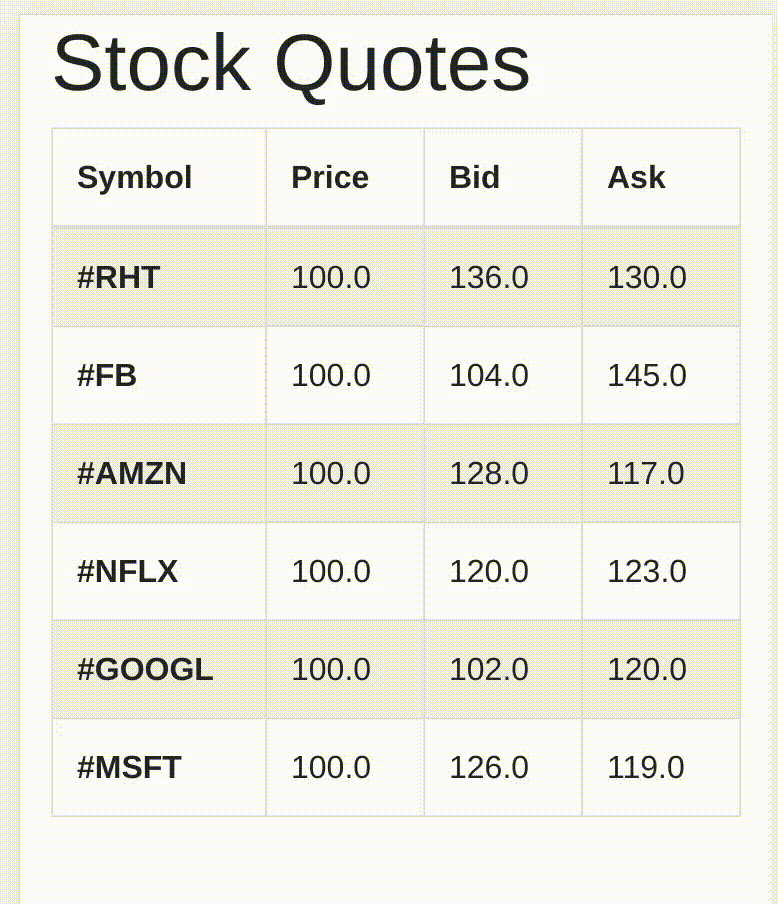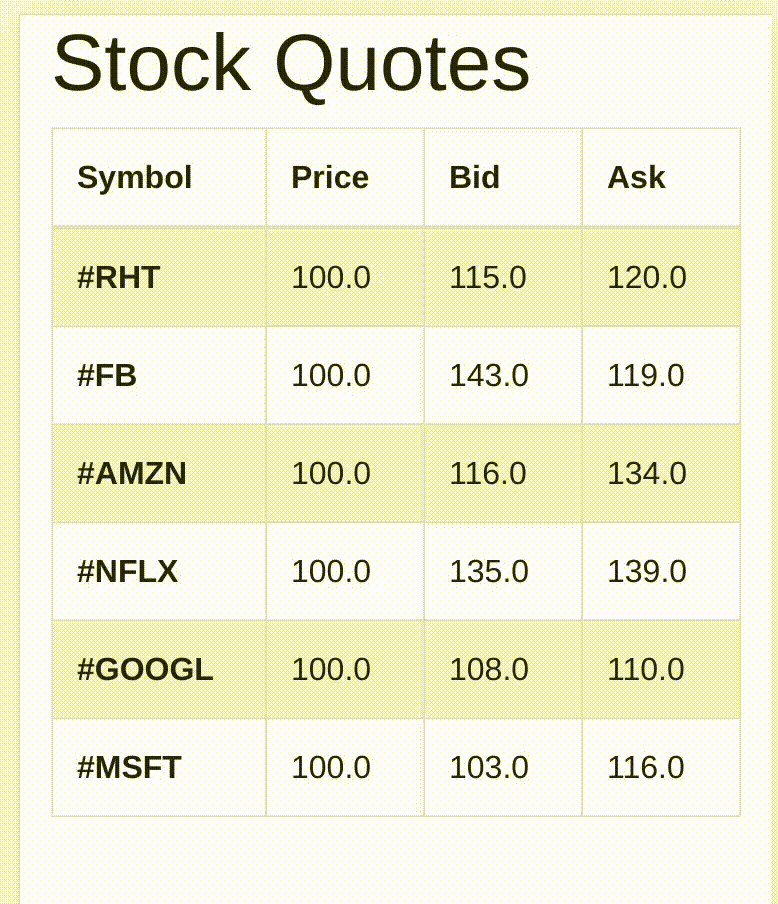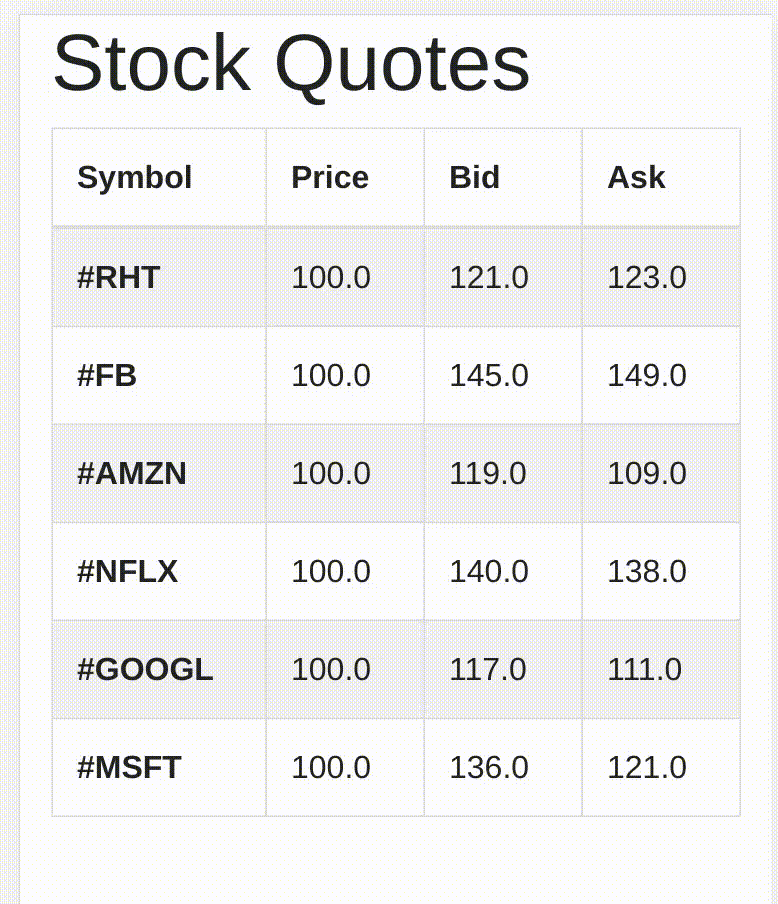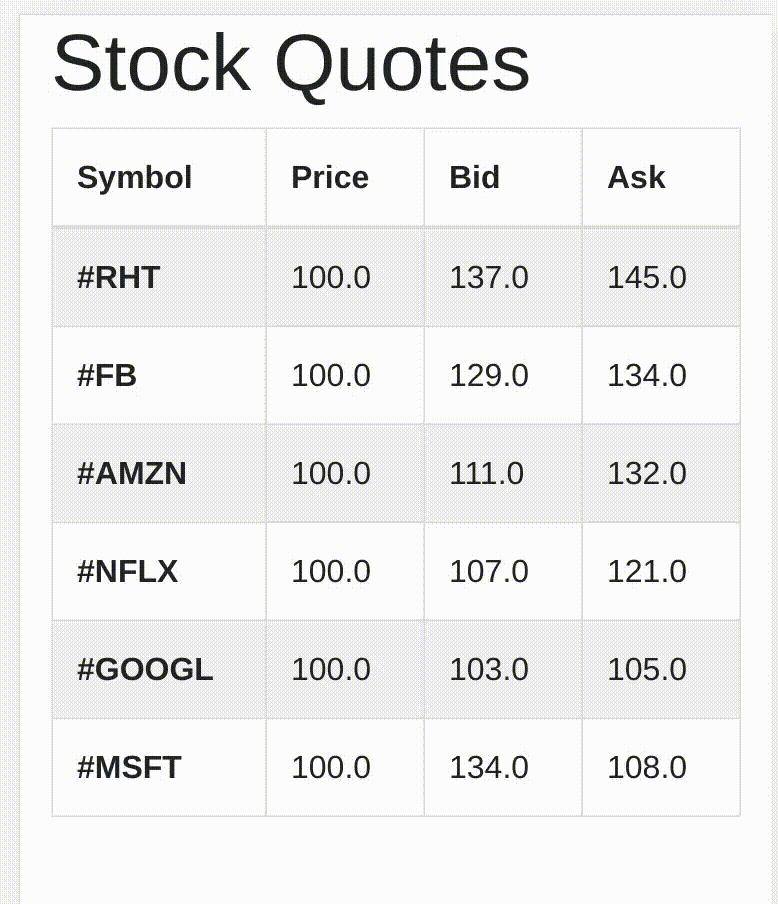
that you can easily run locally or on OpenShift:
oc new-app quay.io/eformat/quote-generator:latest
oc create route edge quote-generator --service=quote-generator --port=8080
and then retrieve the events in the browser or by curl:
curl -H "Content-Type: application/json" --max-time 9999999 -N http://localhost:8080/quotes/stream
So, first challenge - How might we consume these SSE’s using Flink? I found a handy AWS Kinesis SSE demo which i snarfed the SSE/OKHttp code from. I wired this into flinks RichSourceFunction:
So now i could consume this SSE source as a DataStream
In the example, i wire in the stock quotes for NFLX and RHT. Next step, process these streams. Since i am new to flink, i started with a simple print function, then read this stock price example from 2015! cool. So i implemented a simple BuyFunction class that makes stock buy recommendations:
Lastly, it needs to be sent to a sink. Again, i started by using a simple print sink:
Friends of mine have been telling me how much more awesome Pulsar is compared to Kafka so i also tried out sending to a local pulsar container that you can run using:
podman run -it -p 6650:6650 -p 8081:8080 --rm --name pulsar docker.io/apachepulsar/pulsar:2.10.2 bin/pulsar standalone
And forwrded to pulsar using a simple utility class using the pulsar java client:
Then consume the messages to make sure they are there !
podman exec -i pulsar bin/pulsar-client consume -s my-subscription -n 0 persistent://public/default/orders
And i need to write this post as well .. getting it to run in OpenShift …
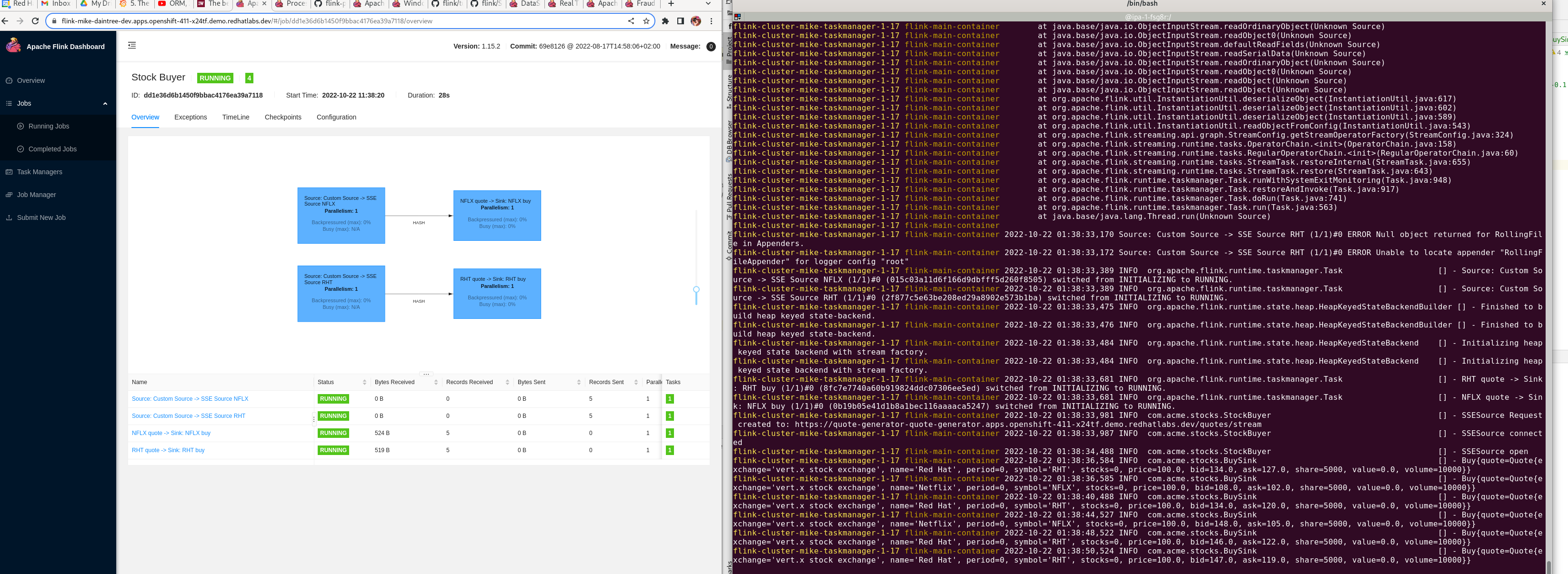
Source code is here - https://github.com/eformat/flink-stocks
