gitops-monorepo
├── applications | Infrastructure and application configurations
├── app-of-apps | Top level pattern to define environments/clusters
├── bootstrap-acm | Bootstrap our HUB cluster
├── policy-collection | All day#2 config is stored as configuration policy
├── README.md | Always provide some Help !
Tag: acm
OpenShift SRE ❤️ GitOps + Policy as Code
24 December 2023
Tags : acm, gitops, policy, openshift
Within the enterprise - deploying and managing a fleet of OpenShift clusters can be a challenge. There are multiple ways and means to achieve your goals. I will lay out my favourite patterns and methods and a few tips and tricks I commonly use. In particular the methodology around using GitOps and Policy as Code.
GitOps, Everything as Code and Kubernetes Native
Everything as Code is the practice of treating all parts of the systems as code. This means storing the configuration in a Source Code repository such as git. By storing the configuration as code, environments can be life-cycled and recreated whenever they are needed. So why go to this effort ?
(1) Traceability - storing your config in git implies controls are in place to track who/why a config changes has been made. Changes can be applied and reverted. Changes can be tracked to a single user who made the change.
(2) Repeatable - moving from one cloud provider to another should be simple in modern application development. Picking a deployment target can be like shopping around for the best price that week. By storing all things as code, systems can be re-created quickly in various providers.
(3) Tested - infrastructure and code can be rolled out, validated, promoted into production environments with confidence and assurance it behaves as expected.
(4) Phoenix Server - no more fear of a servers' configuration drifiting. If a server needs to be patched or just dies, it’s OK. We can recreate it again from the stored configuration.
(5) Shared Understanding - when cross-functional teams use Everything as Code to desribe parts of their Product they are developing together, they increase the shared understanding between Developers and Operations, they speak the same language and use the same frameworks.
So How do we do it - GitOps ?
GitOps is a pattern to manage flow of work from development to production though Git Operations. The concept behind GitOps is quite straightforward.
-
Everything as Code: Git is always the source of truth on what happens in the system
-
Deployments, tests, rollbacks are always controlled through a Git flow
-
No manual deployments/changes: If you need to make a change, you need to make a Git operation such as commit + push, or raise a pull request.
The most popular GitOps tools in use today are ArgoCD and Flux. We use ArgoCD as the GitOps controller in OpenShift. This is supported as the "RedHat OpenShift GitOps Operator". We can align how our teams use and setup GitOps and their tooling - we are following patterns written about here.
When using OpenShift, we have a strong desire to stick to Kubernetes native methods of configuring the cluster, the middleware that runs upon it, as well as the applications - all using k8s native methods. I won’t cover deploying resources outside a cluster all that much - this usually needs other tools to help provision them. Some can be configured using the Operator Pattern, some may need tools like Crossplane to provision against cloud API’s. For now, we will assume that we have a hybrid or public cloud that provides storage, compute and networking services - all made available to us.
Code Structure
Take some time to organise your code. When you scale out your configuration to multiple environments/clusters/clouds - you need to be able to scale out individual bits of your repository, especially using folders. We use Kustomize heavily - and its use of bases and overlays encourages folders as the main mechanism for growth. Helm templating is also in use - because we need the flexibility to template applications even-though there is always a level of fungibility with templating languages.
Our main goal is to keep the code maintainable and discoverable. We need new developers to be able to easily on-board to using the code repo, as we would like to keep the burden of making changes very low. There is a continual tension between having one version of a piece of code that is shared across all your environments, (making it easy to maintain) with the trade-off that the blast radius can be large if an erroneous change is made that causes failures. As our codebase matures - we can code and transition around this tension. For example, we may use copy-and-paste reuse heavily at the start of our efforts to keep the blast radius low (to a single cluster) and gradually migrate the code to a single shared artifact as we become happy with its performance over time.
I like to keep my configuration repo as a git monorepo initially. Code is stored in one simple hierarchy.
The top level is kept quite simple. Applications that may be deployed to different clusters are stored in the application’s folder. We use the ArgoCD app-of-apps pattern to describe Applications that are deployed to each HUB cluster. We have a bootstrap folder for our HUB cluster (which is not GitOps) - we deploy ACM and ArgoCD from here. We could make this GitOps as well - however there are often manual steps required to get the environment ready for use e.g. creating an external Vault integration, creating cloud credentials etc. All other use case e.g. spoke cluster creation, day#2 configuration, application deployments - are done via GitOps.
A common folder structure for a Kustomize based application is shown below for the infrastructure risk compliance application. Here we configure the OpenShift Compliance Operator for all our clusters. We use the base folder for common deployment artifacts to all clusters - including the operator, operator group, scan settings and tailored profiles. We can the use the overlay folder to specify environment (develop | nonprod) and cluster (east | west) specific configuration. In this case we are using the PolicyGenerator in each application definition which is configured to pull secrets from different locations in vault.
applications/compliance/
├── input
│ ├── base
│ │ ├── kustomization.yaml
│ │ ├── namespace.yaml
│ │ ├── operatorgroup.yaml
│ │ ├── scan-setting-binding.yaml
│ │ ├── subscription.yaml
│ │ └── tailored-profile.yaml
│ └── overlay
│ ├── develop
│ │ ├── east
│ │ │ ├── input
│ │ │ │ └── kustomization.yaml
│ │ │ ├── kustomization.yaml
│ │ │ └── policy-generator-config.yaml
│ │ └── west
│ │ ├── input
│ │ │ └── kustomization.yaml
│ │ ├── kustomization.yaml
│ │ └── policy-generator-config.yaml
│ └── nonprod
│ ├── east
│ │ ├── input
│ │ │ └── kustomization.yaml
│ │ ├── kustomization.yaml
│ │ └── policy-generator-config.yaml
│ └── west
│ ├── input
│ │ └── kustomization.yaml
│ ├── kustomization.yaml
│ └── policy-generator-config.yamlThe one time I break this pattern - is when considering the Production environment. Often in highly regulated industries, production must be treated separately and often has stricter change control requirements surrounding it. This may include different git flows. For small, high trust teams, trunk based development is one of the best methods to keep the flow of changes coming! Often the closer you get to production though, a change in git flow techniques is required. So for Production, pull requests only.
NonProduction repo - no PR's required, trunk based development in place.
Production repo - PR's required.The trade-off is of course you now have two repositories, often with duplicate code, and must merge from one to the other often. You also have to handle emergency fixes etc. In practice, this is manageable as long as you follow a Software Delivery Lifecycle where changes are made in lower environments first. Your quality and change failure frequency will be better off by doing this. A common pattern is to split out separate applications into separate git repos - and include them as remote repos once they become mature and stable enough.
Hub and Spoke
Open Cluster Management is an opensource community that supports managing Kubernetes clusters at scale. Red Hat priductises this as "Advanced Cluster Management (ACM)". One of the key concepts is the support of Configuration Policy and Placement on clusters using a hub and spoke design.
The biggest benefit of deploying a HUB cluster with Spokes (managed clusters) is that scale can be achieved through the decoupling of policy based computation and decisions - which happen on the HUB cluster- and then execution - which happens on the target cluster. So execution is completely off-loaded onto the managed cluster itself. Spoke managed clusters do the work and pull configuration from the HUB independently. This means a HUB does not become a single point of failure during steady state operations and Spoke clusters can number in the hundreds or thousands achieving scale.
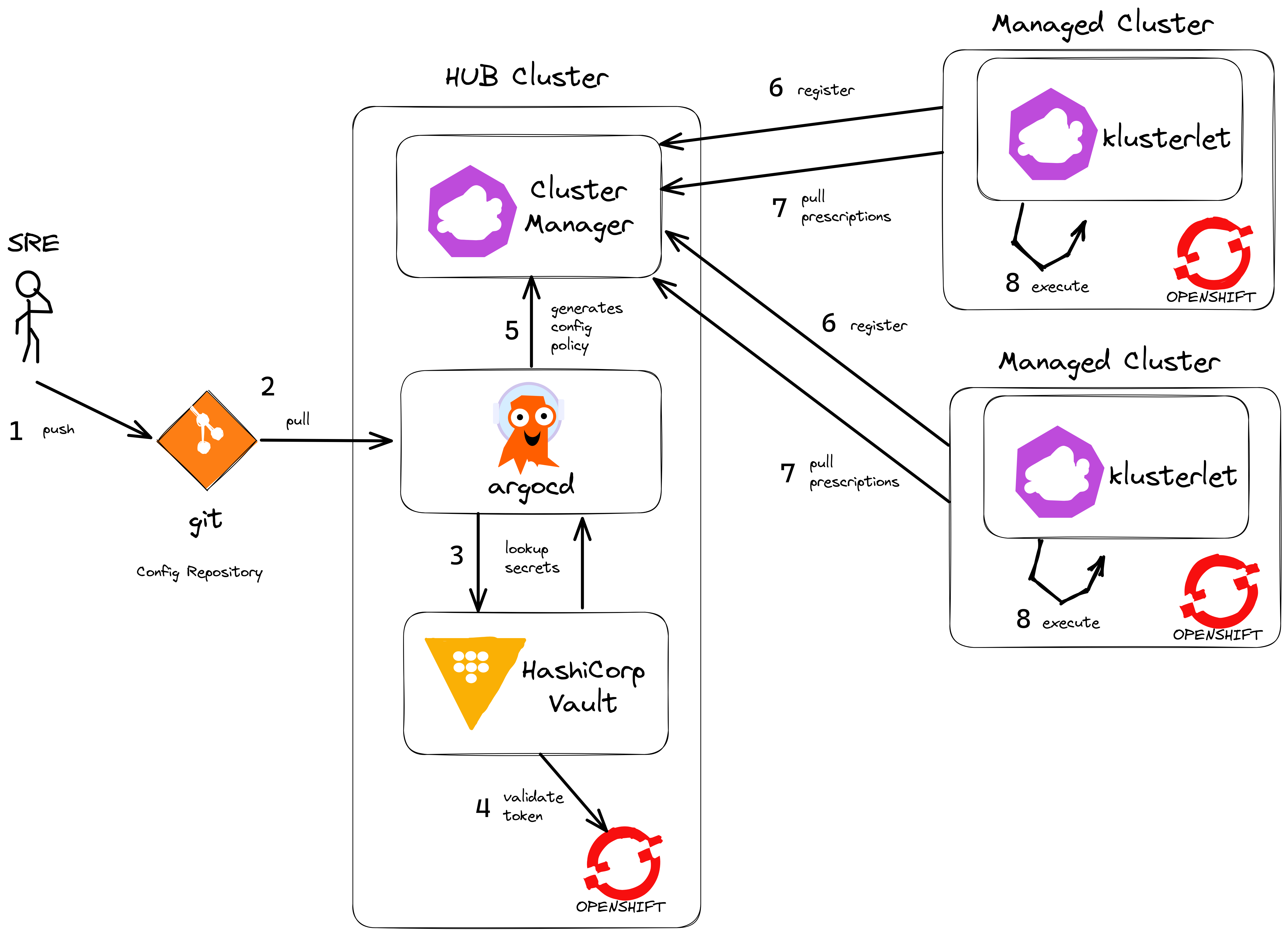
By introducing ArgoCD onto the HUB cluster - we can use it to deploy any application or configuration. The primary method is to package all the code as Configuration Policy. By doing this, we have fantastic visibility into each cluster, we control configration with Git and drift is kept to zero using GitOps - we like to say "if it’s not in git, it’s not real !"
Another benefit of using ArgoCD is to hydrate secrets from external vault providers like Hashicorp Vault (many others are supported). That way, any and all configuration (not just Kubernetes Secrets that can be mounted in pods) can be hydrated with values from our secrets vault provider, thus keeping secret values outside of Git itself.
There are more complex ArgoCD/ACM models available e.g. the multi-cluster pull, push models. However, the benefit here is one of simplicity - we have less moving parts to manage, so it is more anti-fragile. For each environment (develop | nonprod | prod) we deploy separate HUB clusters. That way we can test and promote configuration from the lower environments first (develop | nonprod) before getting to production.
Policy as Code
Policies are one key way for organisations to ensure software is high quality, easy to use and secure. Policy as code automates the decision-making process to codify and enforce policies in our environment. There are generally two types of policies:
-
Configuration Policy
-
Constraint Policy
ACM supports both types of policy. Because OpenShift is architected securely out of the box - there are many day#2 configurations that can be used to manage the platform in the manner required within your organisation.
Managing Operator configurations is one key way, as is applying MachineConfiguration to your cluster or introducing third party configurations. You can get a long way to configuring a secure, spec-compliant cluster without needing to use any Constraint Policy at all. The OpenSource leader in constraint policy is undoubtedly Open Policy Agent (OPA) which uses the rego language to encode constraint policy. There are many other choices that do not require the adoption of a specific language, but rather are pure yaml - Kyverno has wide adoption.
There is an open source repository that hosts example policies for Open Cluster Management.
This is a huge benefit as it provides a way to share policies from the community and vendors, as well as removing the burden of haing to write many custom policies yourself. Policies are organised under the NIST Special Publication 800-53 specification definitions.
If you follow this naming and grouping convention in your Policy annotations - then you can use the Governance Dashboard in ACM to graphically show you this structure as well.
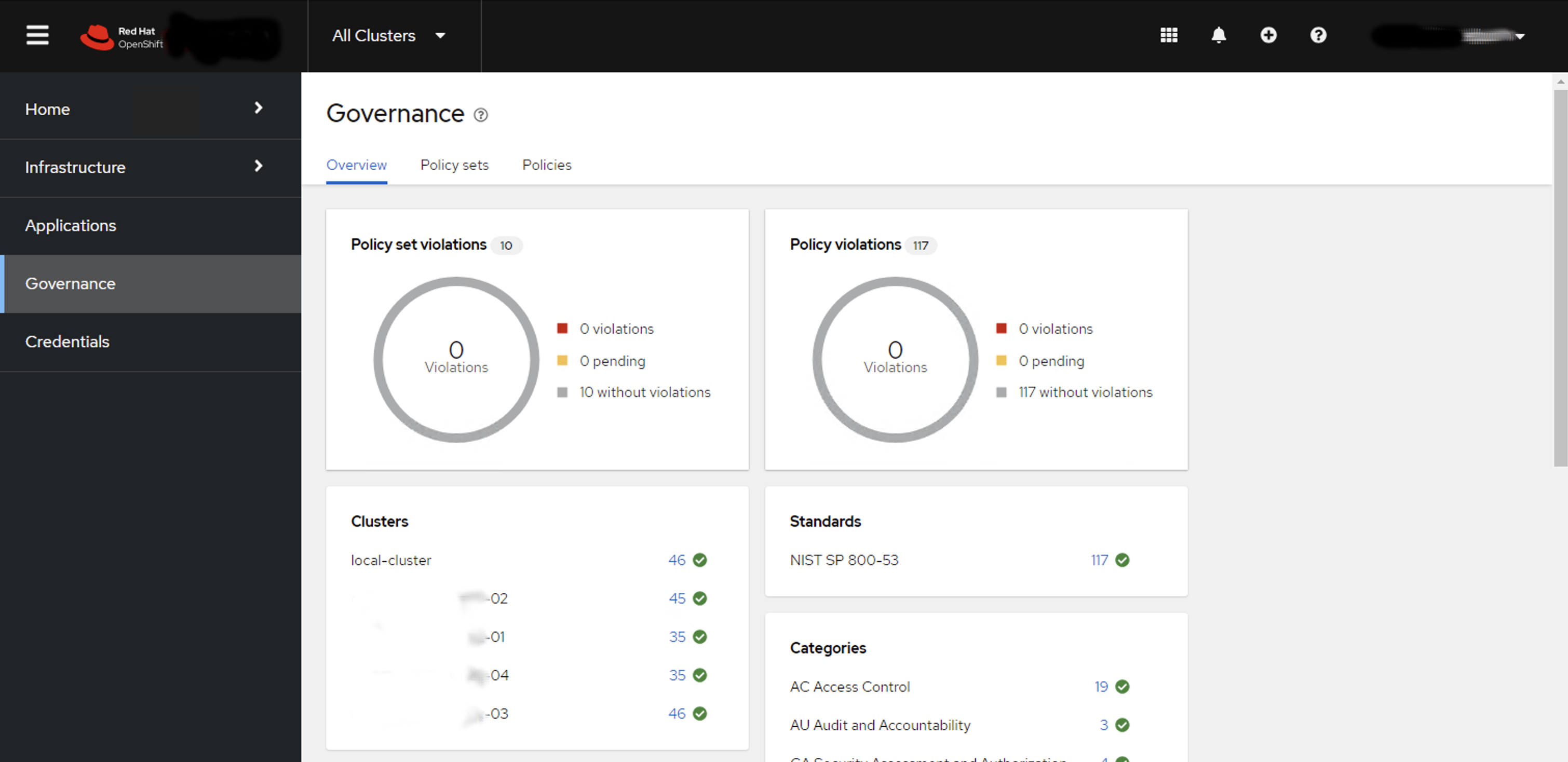
In the above picture we have five OpenShift clusters in our environment using the NIST 800-53 convention for configuration policy. It becomes is easy to overview an environment to check on configuration drift. SRE’s can easily determine that their environment configuration is healthy. They can drill down into individual clusters, or areas of configuration across their entire fleet.
Configuration Drift nearly becomes a thing of the past ! as GitOps and ACM ensure configuration policy is applied to all clusters and environments - so troubleshooting configuration management can generally be performed by exception only saving a lot of time and effort.
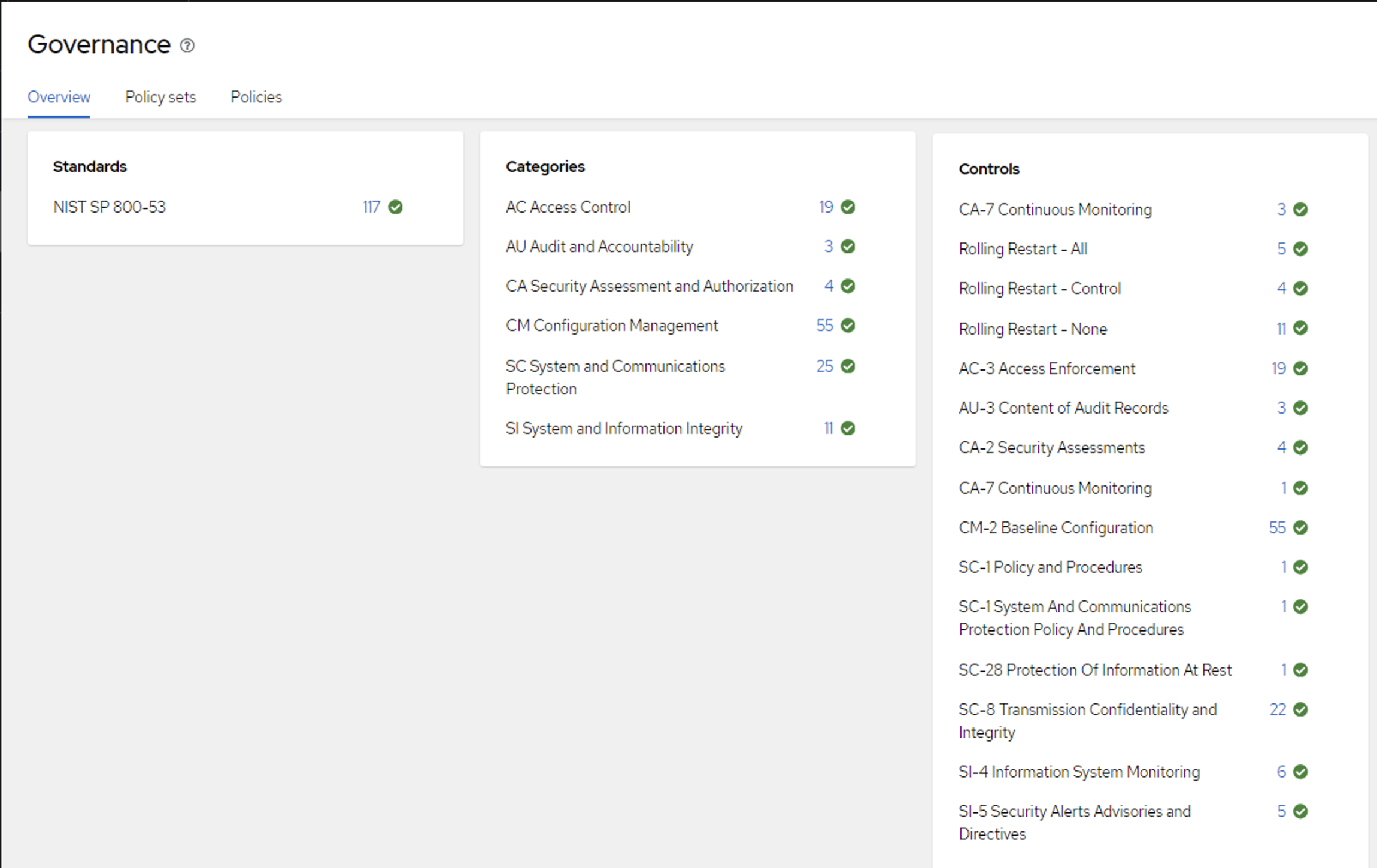
Even with hundreds of policies applied across multiple clusters, the NIST grouping and policy search allows an SRE to easily find individual policies. So if we wanted to check an Access Control policy - we can see if it is applied in multiple dimensions both across clusters and down to individual cluster level.
Writing policy boilerplate can be very time-consuming. I make heavy use of the awesome PolicyGenerator tool that allows you to specify YAML config using Kustomize (or if you compile this PR you can use Helm via Kustomize as well!) and have the policy generated for you. You can see a number of PolicySets that use the PolicyGenerator that can be used straight away in your code base.
App of Apps
In our mono repo, I like to use the ArgoCD App Of Apps pattern to declaratively specify all the applications that exist in each HUB cluster. You can then drop ArgoCD Application YAML definition files into the folder to easily deploy any number of applications.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: develop-app-of-apps
namespace: open-cluster-management-global-set
labels:
rht-gitops.com/open-cluster-management-global-set: policies
spec:
destination:
namespace: open-cluster-management-global-set
server: 'https://kubernetes.default.svc'
project: default
source:
path: app-of-apps/develop/my-dev-hub-cluster-01
directory:
include: "*.yaml"
repoURL: https://git/gitops-monorepo.git
targetRevision: main
syncPolicy:
automated:
selfHeal: true
syncOptions:
- Validate=trueOne thing to note is the careful use of syncPolicy options. I explicitly do not want to set prune: true for example, so leaving deleting turned off. You will want to tune deletion behaviour using Policy, in particular the PolicyGenerator setting called pruneObjectBehavior which can take various values such as None|DeleteAll. It is also worth setting policyAnnotations: {"argocd.argoproj.io/compare-options": "IgnoreExtraneous"} in the PolicyGenerator so that ArgoCD shows the correct sync status.
ArgoCD Vault Plugin
Managing secrets is an important concern from day zero. The two main methods in popluar use today take different approaches. The first has encrypted secrets in the codebase. The second - my preferred, is to keep secret values out of our code base altogether by using a secrets vault. There are many ways to achieve this depending on the type of vault in use and the integration points needed at scale. For the GitOps model I drew out earlier, we can make use of the ArgoCD Vault Plugin and the sidecar pattern to hydrating secrets values in all of our configuration. This has the benefit of being able to hydrate secrets values into Policy code directly as well as creating secrets for pods to mount.
My sidecar configMap for ArgoCD contains the three methods I use to call the AVP plugin using helm, Kustomize or via straight YAML. Note that Kustomize has the helm plugin enabled using these flags --enable-alpha-plugins --enable-helm build:
helm-plugin.yaml: |
apiVersion: argoproj.io/v1alpha1
kind: ConfigManagementPlugin
metadata:
name: argocd-vault-plugin-helm
spec:
init:
command: [sh, -c]
args: ["helm dependency build"]
generate:
command: ["bash", "-c"]
args: ['helm template "$ARGOCD_APP_NAME" -n "$ARGOCD_APP_NAMESPACE" -f <(echo "$ARGOCD_ENV_HELM_VALUES") . | argocd-vault-plugin generate -s open-cluster-management-global-set:team-avp-credentials -']
kustomize-plugin.yaml: |
apiVersion: argoproj.io/v1alpha1
kind: ConfigManagementPlugin
metadata:
name: argocd-vault-plugin-kustomize
spec:
generate:
command: ["sh", "-c"]
args: ["kustomize --enable-alpha-plugins --enable-helm build . | argocd-vault-plugin -s open-cluster-management-global-set:team-avp-credentials generate -"]
vault-plugin.yaml: |
apiVersion: argoproj.io/v1alpha1
kind: ConfigManagementPlugin
metadata:
name: argocd-vault-plugin
spec:
generate:
command: ["sh", "-c"]
args: ["argocd-vault-plugin -s open-cluster-management-global-set:team-avp-credentials generate ./"]And from our ArgoCD ApplicationSet or Application all you need to do is specify the plugin name:
plugin:
name: argocd-vault-plugin-kustomizeYou can read more about it here.
Hope you Enjoy! 🔫🔫🔫
ACM & ArgoCD for Teams
17 February 2023
Tags : openshift, argocd, acm, gitops
Quickly deploying ArgoCD ApplicationSets using RHACM’s Global ClusterSet
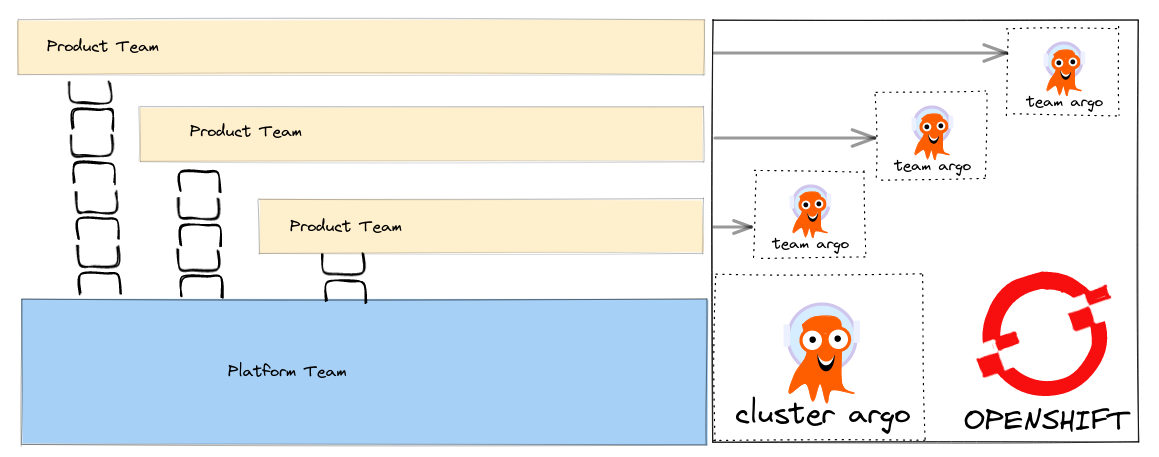
I have written about how we can align our Tech to setup GitOps tooling so that it fits with our team structure.
How can we make these patterns real using tools like Advanced Cluster Manager (ACM) that help us deploy to a fleet of Clusters ? ACM supports Policy based deployments so we can track compliance of our clusters to the expected configuration management policy.
The source code is here - https://github.com/eformat/acm-gitops - git clone it so you can follow along.
Global ClusterSet’s
When a cluster is managed in ACM there are several resources created out of the box you can read about them here in the documentation. This includes a namespace called open-cluster-management-global-set. We can quickly deploy ApplicationSet’s in this global-namespace that generates Policy to create our team based ArgoCD instances.
We can leverage the fact that ApplicationSet’s can be associated with a Placement - that way we can easily control where our Policy and Team ArgoCD’s are deployed across our fleet of OpenShift clusters by using simple label selectors for example.
Bootstrap a Cluster Scoped ArgoCD for our Policies
We are going Bootstrap a cluster-scoped ArgoCD instance into the open-cluster-management-global-set namespace.
We will deploy our Team ArgoCD’s using ACM Policy that is generated using the PolicyGenerator tool which you can read about here from its' reference file.
Make sure to label the cluster’s where you want to deploy to with useglobal=true.
oc apply -f bootstrap-acm-global-gitops/setup.yamlThis deploys the following resources:
-
SubscriptionResource - The GitOps operatorSubscription, including disabling the default ArgoCD and setting cluster-scoped connections for our namespaces - see theARGOCD_CLUSTER_CONFIG_NAMESPACESenv.var that is part of theSubscriptionobject. If your namespace is not added here, you will get namespace scoped connections for your ArgoCD, rather than all namespaces. -
GitOpsClusterResource - This resource provides a Connection between ArgoCD-Server and the Placement (where to deploy exactly the Application). -
PlacementResource - We use aPlacementresource for this global ArgoCD which deploys to a fleet of Clusters, where the Clusters needs to be labeled withuseglobal=true. -
ArgoCDResource - The CR for our global ArgoCD where we will deploy Policy. We configure ArgoCD to download thePolicyGeneratorbinary, and configure kustomize to run with the setting:
kustomizeBuildOptions: --enable-alpha-pluginsDeploy the Team Based ArgoCD using Generated Policy
We are going to deploy ArgoCD for two teams now using the ACM PolicyGenerator.
The PolicyGenerator runs using kustomize. We specify the generator-input/ folder - that holds our YAML manifests for each ArgoCD - in this case one for fteam, one for zteam.
You can run the PolicyGenerator from the CLI to test it out before deploying - download it using the instructions here e.g.
kustomize build --enable-alpha-plugins team-gitops-policy/We specify the placement rule placement-team-argo - where the Clusters needs to be labeled with teamargo=true.
We add some default compliance and control labels for grouping purposes in ACM Governance.
We also set the pruneObjectBehavior: "DeleteAll so that if we delete the ApplicationSet the generated Policy s deleted and all objects are removed. For this to work, we must also set the remediationAction to enforce for our Policies.
One last configuration is to set the ArgoCD IgnoreExtraneous compare option - as Policy is generated we do not want ArgoCD to be out of sync for these objects.
apiVersion: policy.open-cluster-management.io/v1
kind: PolicyGenerator
metadata:
name: argocd-teams
placementBindingDefaults:
name: argocd-teams
policyDefaults:
placement:
placementName: placement-team-argo
categories:
- CM Configuration Management
complianceType: "musthave"
controls:
- CM-2 Baseline Configuration
consolidateManifests: false
disabled: false
namespace: open-cluster-management-global-set
pruneObjectBehavior: "DeleteAll"
remediationAction: enforce
severity: medium
standards:
- generic
policyAnnotations: {"argocd.argoproj.io/compare-options": "IgnoreExtraneous"}
policies:
- name: team-gitops
manifests:
- path: generator-input/Make sure to label the cluster’s where you want to deploy to with teamargo=true.
To create our Team ArgoCD’s run:
oc apply -f applicationsets/team-argo-appset.yamlTo delete them, remove the AppSet
oc delete appset team-argoSummary
You can now take this pattern and deploy it across multiple clusters that are managed by ACM. You can easily scale out the number of Team Based ArgoCD and have fine grained control over their individual configuration including third party plugins like Vault. ACM offers a single plane of glass to check if your clusters are compliant to the generated policies, and if not - take remedial action.
You can see the code in action in this video.
🏅Enjoy !!
